[TOC]
1.urllib的使用 urllib.request ——打开和读取url
urllib.error ——包含urllib.request抛出的异常
urllib.parse ——用于解析url
urllib.robotparser ——用于解析robots.txt文件
urlopen网址请求 1 2 3 4 5 6 import urllib.request #导入模块 response = urllib.request.urlopen('https://cn.bing.com/') #使用urlopen方法打开网页 print(response.read().decode('utf-8')) #使用read方法读取网页,decode('utf-8')表示把utf-8设置为编码方式
如果网速比较慢或者所请求的网站打开时比较缓慢,可以设置一个超时限制,这时需要加入timeout参数
1 2 3 4 import urllib.request response = urllib.request.urlopen('https://cn.bing.com/',timeout=10) #设置超时时间为10s print(response.read().decode('utf-8'))
网页的保存和异常处理 把代码保存到HTML,如网页打开时读取失败,则通过Exception捕获异常
1 2 3 4 5 6 7 8 try: x=urllib.request.urlopen('https://cn.bing.com/') #print(x.read()) save = open('1.html','w') save.write(str(x.read())) save.close() except Exception as e: print(str(e))
构造请求对象Request 1 2 3 4 5 6 7 import urllib.request request = urllib.request.Request("https://cn.bing.com/") #用Request构造Requests对象类 response = urllib.request.urlopen(request) #用urlopen打开网页 print(response.read().decode('utf-8')) #用read打印内容
添加请求头 构造的基本格式为:headers={‘User-Agent’:’请求头’}
找请求头:检查——网络——刷新——标头——User-Agent,将它复制出来
请求网址url:当前打开的网页
代码方法:200 OK ,表示请求打开网址成功
cookie:用于识别用户身份
User-Agent:用户代理
1 2 3 4 5 6 from urllib import request url='https://sakitamarin.github.io/2024/06/29/%E6%B8%B8%E6%88%8F%E8%AE%BE%E8%AE%A1-%E7%AC%94%E8%AE%B0/' headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'} req=request.Request(url=url,headers=headers) response=request.urlopen(req) print(response.read().decode('utf-8'))
继续在请求头中添加cookie,这样便于身份识别。每一个用户登录一个网站都有对应的cookie。
SSL认证 用于没有SSL证书的网站。
1 2 3 4 5 6 7 8 9 10 import urllib import urllib.request #对ssl进行设置,忽略警告,继续进行访问 import ssl ssl._create_default_https_context = ssl._create_unverified_context #不带s不会进行认证的 url = 'http://agedmw2.com/acg/71844/4.html' response = urllib.request.urlopen(url=url) print(response.read().decode('utf-8'))
强制https认证 1 2 3 4 5 6 7 8 9 10 11 import requests #urllib3 官方强制验证https安全证书,解决警告 import urllib3 urllib3.disable_warnings() url = 'https://www.12306.cn/mormhweb/' #requests操作起来简单 False不要进行认证 response = requests.get(url=url,verify = False) #设置返回编码 response.encoding = 'utf-8' print(response.text)
2.Requests中get的用法 模块安装命令:pip install request
代码获取 1 2 3 import requests r = requests.get('https://cn.bing.com/?mkt=zh-CN') print(r.text)
status_code可以获取请求结果的状态,text方法以文本形式获取代码
1 2 3 4 import requests u=requests.get('https://www.weibo.com/') print(u.status_code)#打印状态码 print(u.text)#打印文本
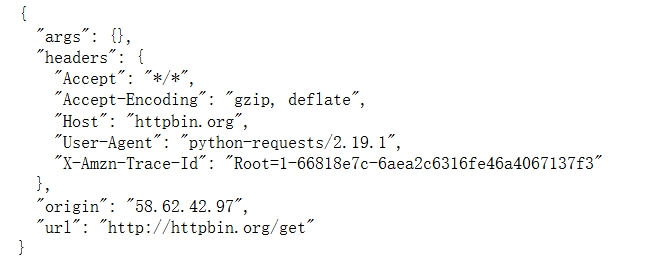
构建请求 origin:个人ip
url:读者请求的网址
1 2 3 import requests r = requests.get('http://httpbin.org/get') print(r.text)
获取cookie
名字——name
值——value
过期时间——Expries/Max-Age
作用路径——path
所在域名——domain
使用cookie进行安全连接——secure
1 2 3 4 5 6 7 8 9 10 import requests headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36' }#请求头 url='https://www.csdn.net/?spm=1011.2124.3001.5359' r=requests.get(url=url,headers=headers) cookiejar = r.cookies cookiedict = requests.utils.dict_from_cookiejar(cookiejar) print (cookiejar) print(cookiedict)
添加请求头 1 2 3 4 5 6 import requests headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36' } r = requests.get("https://www.zhihu.com/explore", headers=headers) print(r.text)